服务环境背景话术
使用 Siege 和 ab 作为压测工具
siege 英[siːdʒ]
话术:https://wangxinglong.com.cn/index.php/archives/87/
具体操作:https://wangxinglong.com.cn/index.php/archives/88/
强调我们的日均pv在千万级,也就是每天的pv在1000万左右,日活(uv)在80万左右,QPS(每秒请求数)1000左右 峰值1200,时间段在晚上,因为晚上看视频的人多,并发数最高
而经过测试,我们单台服务器的极限值是300左右(uwsgi+django)
单台mysql连接数维持在1200个左右
所以nginx负载均衡部署了8台机器,其中两台作为备用机
mysql主从分离集群部署了4台从机,其中一台作为备用机
前端做了cdn缓存和做了gizp压缩 webpack优化,精简http请求数,视频缩略图延迟加载
基本在打出富裕(超出极限负载30%左右)的前提下,在高并发高负载环境下可以正常运营(但是不排除特殊情况下出现的宕机,比如ddos攻击)
Linux查看系统负载常用命令
top 查看实时负载,3秒一刷新
cat /proc/cpuinfo :即可查看CPU信息,几个processor即为几个CPU;
sar:可以监控系统所有资源状态,sar -n DEV查网卡流量历史、sar -q 查看历史负载,最有用的就是查网卡流量,流量过大:rxpck/s大于4000,或者rxKB/s大于5000,则很有可能被攻击了,需要抓包分析;
free:查看当前系统的总内存大小以及使用内存的情况;
ps:查看进程,ps aux 或者 ps -elf,常和管道符一起使用,查看某个进程或者它的数量;
netstat:查看端口,netstat -lnp用于打印当前系统启动了哪些端口,netstat -an用于打印网络连接状况;
tcpdump:抓包工具分析数据包,知道有哪些IP在攻击;可以将内容写入指定文件1.cap中,显示包的内容,不加-w屏幕上显示数据流向;
wireshark:抓包工具,可以临时用该命令查看当前服务器上的web请自动化运维系统
背景
在软件开发生命周期中,遇到了两次瓶颈。第一次瓶颈是在需求阶段和开发阶段之间,针对不断变化的需求,对软件开发者提出了高要求,后来出现了敏捷方法论,强调适应需求、快速迭代、持续交付。第二个瓶颈是在开发阶段和构建部署阶段之间,大量完成的开发任务可能阻塞在部署阶段,影响交付,于是有了自动化运维系统(DevOps)。
DevOps的三大原则:
1、基础设施即代码(Infrastructure as Code) DeveOps的基础是将重复的事情使用自动化脚本或软件来实现,例如Docker(容器化)、Jenkins(持续集成)、Puppet(基础架构构建)、Vagrant(虚拟化平台)等
2、持续交付(Continuous Delivery) 持续交付是在生产环境发布可靠的软件并交付给用户使用。而持续部署则不一定交付给用户使用。涉及到2个时间,TTR(Time to Repair)修复时间,TTM(Time To Marketing)产品上线时间。要做到高效交付可靠的软件,需要尽可能的减少这2个时间。部署可以有多种方式,比如蓝绿部署、金丝雀部署等。
3、协同工作(Culture of Collaboration) 开发者和运维人员必须定期进行密切的合作。开发应该把运维角色理解成软件的另一个用户群体。协作有几个的建议:1、自动化(减少不必要的协作);2、小范围(每次修改的内容不宜过多,减少发布的风险);3、统一信息集散地(如wiki,让双方能够共享信息);4、标准化协作工具(比如jenkins)
在很多初创公司和中小型企业里,运维还停留在“刀耕火种”的原始状态,这里所说的“刀”和“火”就是运维人员的远程客户端,例如SecureCRT和Windows远程桌面。
在这种工作方式下,服务器的安装、初始化,软件部署、服务发布和监控都是通过手动方式来完成的,需要运维人员登录到服务器上,一台一台去管理和维护。这种非并发的线性工作方式是制约效率的最大障碍。
同时,因为手动的操作方式过于依赖运维人员的执行顺序和操作步骤,稍有不慎即可能导致服务器配置不一致,也就是同一组服务器的配置上出现差异。有时候,这种差异是很难直接检查出来的,例如在一个负载均衡组里面个别服务器的异常就很难发现。
随着业务的发展,服务器数量越来越多,运维人员开始转向使用脚本和批量管理工具。脚本和批量管理工具与“刀耕火种”的工作方式相比,确实提升了效率和工程质量。
项目地址
版本库地址: https://gitee.com/QiHanXiBei/spug/tree/master
演示地址: https://spug.qbangmang.com 用户名:admin 密码:spug
具体功能话术:
User 用户管理
Rbac 权限管理
CMDB 资产管理
也就是服务器管理 通过后台对服务器集群进行管理
其中可以对服务器进行配置,远程命令行连接,连接服务器挂载的docker服务器,对docker映射端口号进行修改和配置
Task 任务计划管理
可以对计划任务进行配置和管理,例如发送邮件,发送短信,定时重启服务等等
CI/CD 部署、发布管理
集成jenkins,将冗长的代码拉取,克隆完全编程在网页端一键式的部署流程
Config File 配置文件管理
对项目的config文件统一管理,对重要文件做到一键式迁移
Monitor 监控
对服务器监控,监控服务器的cpu和内存占用
集成supervisor对后台服务做监控,是否宕机,服务进程监控
对站点监控,对集群网站的带宽以及http请求进行监控
Alarm 报警
如果出现数据异常或者内存占用过高,cpu占用过高的情况,磁盘空间不够等紧急情况
进行发邮件或者短信预警
工单系统
1、解决的问题
1. 工作流程不统一,大量复杂工作流程,让人眼花缭乱(工单的边界比较模糊)。
2. 邮寄审批严重耗时、效率低下(特别是很多大部门leader被淹没在邮件中)。
3. 多部门协同工作,进度无法把控(到处拉群讨论)。
4. 大量人员每天做重复性工作,严重浪费人力成本。
2、工单系统模块
1) 用户管理
用户表、部门表、角色表 (设置代理人)
2)工单模板配置
工单模板配置 ==》 审批流程配置 ==》 自动化工单配置
3)工单实例化
申请人工单 (审批中、被退回、完成)
审批人子工单 (待处理、通过、退回、否决、确认)
自动化工单 (待执行、完成、执行异常)
4)工单通知
邮件、企业微信、超时报警
5)移动审批
企业微信审批
6)工单报表
工单类型、工单处理量、满意度统计
什么是Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker与虚拟机比较
作为一种轻量级的虚拟化方式,Docker在运行应用上跟传统的虚拟机方式相比具有显著优势:
Docker容器很快,启动和停止可以在秒级实现,这相比传统的虚拟机方式要快得多。 Docker容器对系统资源需求很少,一台主机上可以同时运行数千个Docker容器。 Docker通过类似Git的操作来方便用户获取、分发和更新应用镜像,指令简明,学习成本较低。 Docker通过Dockerfile配置文件来支持灵活的自动化创建和部署机制,提高工作效率。

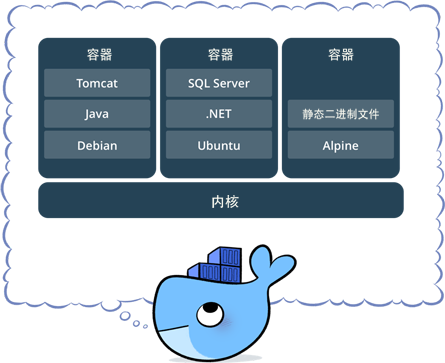
Docker构架
Docker使用C/S架构,Client 通过接口与Server进程通信实现容器的构建,运行和发布。client和server可以运行在同一台集群,也可以通过跨主机实现远程通信。
Docker优势
更高效的利用系统资源 由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,Docker 对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。
更快速的启动时间 传统的虚拟机技术启动应用服务往往需要数分钟,而 Docker 容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
一致的运行环境 开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而 Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 「这段代码在我机器上没问题啊」 这类问题。
持续交付和部署 对开发和运维(DevOps)人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。
使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。开发人员可以通过 Dockerfile 来进行镜像构建,并结合 持续集成(Continuous Integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合 持续部署(Continuous Delivery/Deployment) 系统进行自动部署。
而且使用 Dockerfile 使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像。
更轻松的迁移 由于 Docker 确保了执行环境的一致性,使得应用的迁移更加容易。Docker 可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的。因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
更轻松的维护和扩展 Docker 使用的分层存储以及镜像的技术,使得应用重复部分的复用更为容易,也使得应用的维护更新更加简单,基于基础镜像进一步扩展镜像也变得非常简单。此外,Docker 团队同各个开源项目团队一起维护了一大批高质量的 官方镜像,既可以直接在生产环境使用,又可以作为基础进一步定制,大大的降低了应用服务的镜像制作成本。
Docker核心概念
镜像(image) Docker 镜像(Image)就是一个只读的模板。例如:一个镜像可以包含一个完整的操作系统环境,里面仅安装了 Apache 或用户需要的其它应用程序。镜像可以用来创建 Docker 容器,一个镜像可以创建很多容器。Docker 提供了一个很简单的机制来创建镜像或者更新现有的镜像,用户甚至可以直接从其他人那里下载一个已经做好的镜像来直接使用。
仓库(repository) 仓库(Repository)是集中存放镜像文件的场所。有时候会把仓库和仓库注册服务器(Registry)混为一谈,并不严格区分。实际上,仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签(tag)。
仓库分为公开仓库(Public)和私有仓库(Private)两种形式。最大的公开仓库是 Docker Hub,存放了数量庞大的镜像供用户下载。国内的公开仓库包括 时速云 、网易云 等,可以提供大陆用户更稳定快速的访问。当然,用户也可以在本地网络内创建一个私有仓库。
当用户创建了自己的镜像之后就可以使用 push 命令将它上传到公有或者私有仓库,这样下次在另外一台机器上使用这个镜像时候,只需要从仓库上 pull 下来就可以了。
Docker 仓库的概念跟 Git 类似,注册服务器可以理解为 GitHub 这样的托管服务。
容器(container) Docker 利用容器(Container)来运行应用。容器是从镜像创建的运行实例。它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台。可以把容器看做是一个简易版的 Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
容器的定义和镜像几乎一模一样,也是一堆层的统一视角,唯一区别在于容器的最上面那一层是可读可写的。
Docker隔离性
Docker容器本质上是宿主机上的进程。Docker 通过namespace实现了资源隔离,通过cgroups实现资源限制,通过写时复制机制(Copy-on-write)实现了高效的文件操作。
Linux内核实现namespace的主要目的之一就是实现轻量级虚拟化(容器)服务。在同一个namespace下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,仿佛自己置身于一个独立的系统环境中,以达到独立和隔离的目的。
一般,Docker容器需要并且Linux内核也提供了这6种资源的namespace的隔离: UTS : 主机与域名 IPC : 信号量、消息队列和共享内存 PID : 进程编号 NETWORK : 网络设备、网络栈、端口等 Mount : 挂载点(文件系统) User : 用户和用户组 Pid namespace
用户进程是lxc-start进程的子进程,不同用户的进程就是通过pid namespace隔离开的,且不同namespace中可以有相同PID,具有以下特征: 1、每个namespace中的pid是有自己的pid=1的进程(类似/sbin/init进程) 2、每个namespace中的进程只能影响自己的同一个namespace或子namespace中的进程 3、因为/proc包含正在运行的进程,因此而container中的pseudo-filesystem的/proc目录只能看到自己namespace中的进程 4、因为namespace允许嵌套,父进程可以影响子namespace进程,所以子namespace的进程可以在父namespace中看到,但是具有不同的pid Net namespace
有了pid namespace ,每个namespace中的pid能够相互隔离,但是网络端口还是共享host的端口。网络隔离是通过netnamespace实现的, 每个net namespace有独立的network devices, IP address, IP routing tables, /proc/net目录,这样每个container的网络就能隔离开来, LXC在此基础上有5种网络类型,docker默认采用veth的方式将container中的虚拟网卡同host上的一个docker bridge连接在一起
IPC namespace Container中进程交互还是采用linux常见的进程间交互方法(interprocess communication-IPC)包括常见的信号量、消息队列、内存共享。然而同VM不同, container的进程交互实际是host具有相同pid namespace中的进程间交互,因此需要在IPC资源申请时加入namespace信息,每个IPC资源有一个唯一的32bit ID Mnt namespace 类似chroot ,将一个进程放到一个特定的目录执行,mnt namespace允许不同namespace的进程看到的文件结构不同,这样每个namespace中的进程所看到的文件目录被隔离开了,同chroot不同,每个namespace中的container在/proc/mounts的信息只包含所在namespace 的mount point
Uts namespace UTS(UNIX Time sharing System)namespace允许每个container拥有独立地hostname和domain name,使其在网络上被视作一个独立的节点而非Host上的一个进程
User namespace 每个container可以有不同的user和group id ,也就是说可以container内部的用户在container内部执行程序而非 Host上的用户
Nginx负载均衡
正向代理,是在用户端的。比如需要访问某些国外网站,我们可能需要购买vpn。 并且vpn是在我们的用户浏览器端设置的(并不是在远端的服务器设置)。
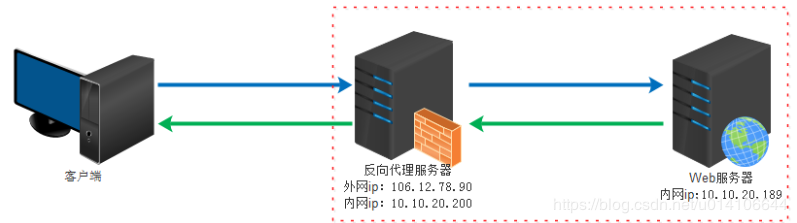
反向代理是作用在服务器端的,是一个虚拟ip(VIP)。对于用户的一个请求,会转发到多个后端处理器中的一台来处理该具体请求。
Nginx一般作为反向代理服务器来实现反向代理来转发处理请求,同时也可以作为静态资源服务器来加快静态资源的获取和处理。
反向代理是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。客户端是无感知代理的存在的,反向代理对外都是透明的,访问者者并不知道自己访问的是一个代理。因为客户端不需要任何配置就可以访问。
作用:保证内网的安全,可以使用反向代理提供WAF功能,阻止web攻击;负载均衡,通过反向代理服务器来优化网站的负载
Nginx架构
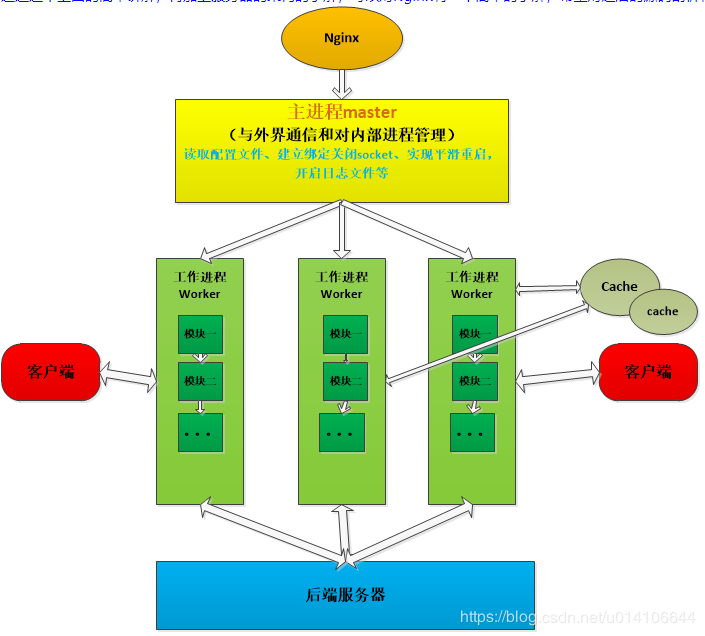
Nginx采用多进程方式,一个Master与多个Worker进程。客户端访问请求通过负载均衡配置来转发到不同的后端服务器依次来实现负载均衡。
Nginx负载均衡策略
Nginx负载均衡策略主要有 轮询,加权轮询,最少连接数以及IP Hash。
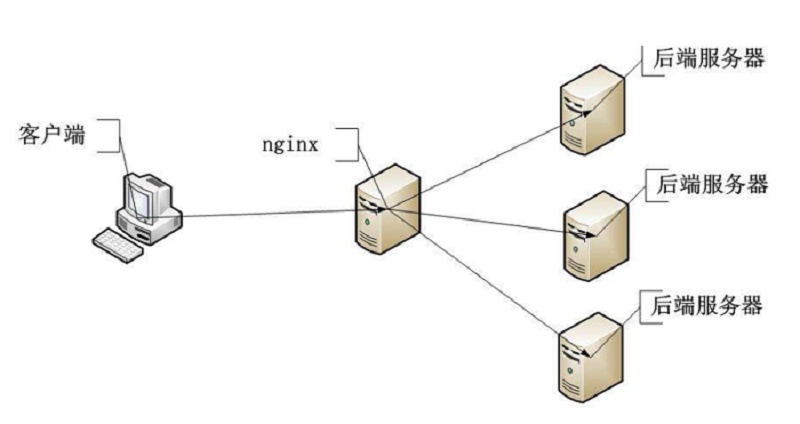
轮询策略: 实现请求的按顺序转发,即从服务srv1--srv2--srv3依次来处理请求

加权轮询策略: 请求将按照服务器的设置权重来实现请求转发和处理,如下所示,最终请求处理数将为3:1:1,一般情况下加权的依据是根据服务器配置来决定的,即配置好的机器分配的权重高 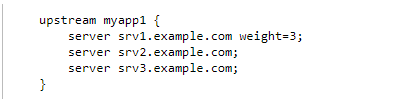
最少连接数策略: 请求将转发到连接数较少的服务器上 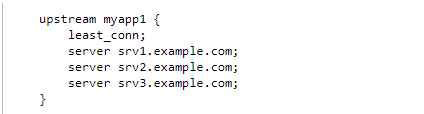
Ip Hash策略: web服务需要共享session,使用该策略可以实现某一客户端的请求固定转发至某一服务器 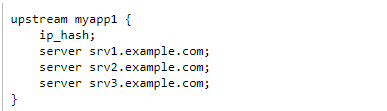
ip_hash算法的原理很简单,根据请求所属的客户端IP计算得到一个数值,然后把请求发往该数值对应的后端。
所以同一个客户端的请求,都会发往同一台后端,除非该后端不可用了。ip_hash能够达到保持会话的效果。
ip_hash是基于round robin的,判断后端是否可用的方法是一样的。
for (i = 0; i < 3; i++) {
hash = (hash * 113 + iphp->addr[i]) % 6271; //iphp->addr[i]为ip的点分十进制法的第i段
}hash3就是计算所得的数值,它只和初始数值hash0以及客户端的IP有关。
for循环 i取 012三个值,而ip的点分十进制表示方法将ip分成四段(如:192.168.1.1),但是这里循环时只是将ip的前三个端作为参数加入hash函数。这样做的目的是保证ip地址前三位相同的用户经过hash计算将分配到相同的后端server。
作者的这个考虑是极为可取的,因此ip地址前三位相同通常意味着来着同一个局域网或者相邻区域,使用相同的后端服务让nginx在一定程度上更具有一致性。
第二步,根据计算所得数值,找到对应的后端。
w = hash3 % total_weight;
while (w >= peer->weight) {
w -= peer->weight;
peer = peer->next;
p++;
}total_weight为所有后端权重之和。遍历后端链表时,依次减去每个后端的权重,直到w小于某个后端的权重。
选定的后端在链表中的序号为p。因为total_weight和每个后端的weight都是固定的,所以如果hash3值相同,
则找到的后端相同。
Supervisor
Supervisor
是用Python开发的一个client/server服务,是Linux/Unix系统下的一个进程管理工具,不支持Windows系统。它可以很方便的监听、启动、停止、重启一个或多个进程。用Supervisor管理的进程,当一个进程意外被杀死,supervisort监听到进程死后,会自动将它重新拉起,很方便的做到进程自动恢复的功能,不再需要自己写shell脚本来控制。
说白了,它真正有用的功能是俩个将非daemon(守护进程)程序变成deamon方式运行对程序进行监控,当程序退出时,可以自动拉起程序。
但是它无法控制本身就是daemon的服务。
具体安装和配置流程参照 https://v3u.cn/Index_a_id_76
Fastdfs
FastDFS是一个开源的分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。可以说它就是为互联网而生,为大数据而生的。
FastDFS服务端有两个角色:跟踪器(tracker)和存储节点(storage)。跟踪器主要做调度工作,在访问上起负载均衡的作用。 存储节点存储文件,完成文件管理的所有功能:存储、同步和提供存取接口,FastDFS同时对文件的meta data进行管理。跟踪器和存储节点都可以由多台服务器构成。跟踪器和存储节点中的服务器均可以随时增加或下线而不会影响线上服务。其中跟踪器中的所有服务器都是对等的,可以根据服务器的压力情况随时增加或减少。

1 解决海量存储,同时存储容量扩展方便。
2 解决文件内容重复,如果用户上传的文件重复(文件指纹一样),那么系统只有存储一份数据,值得一提的是,这项技术目前被广泛应用在网盘中。
3 结合Nginx提高网站读取图片的效率。
具体搭建:https://v3u.cn/a_id_78 通过python交互:https://v3u.cn/Index_a_id_79
其排重原理为:
FastDFS的storage server每次上传均计算文件的hash值,然后从FastDHT服务器上进行查找比对,如果没有返回,则写入hash,并将文件保存;如果有返回,则建立一个新的文件链接(软链),不保存文件。
自动化部署 Jenkins
Jenkins是目前非常流行的一款持续集成工具,可以帮助大家把更新后的代码自动部署到服务器上运行,整个流程非常自动化,你可以理解为部署命令操作的可视化界面。
